Deepseekの驚くほど安価なAIモデルは、業界の巨人に挑戦しています。 中国のスタートアップは、強力なDeepseek V3
をわずか600万ドルで訓練したと主張しており、2048 GPUのみを利用して、競合他社を大幅に下げています。 ただし、この一見低コストは、はるかに大きな投資に裏付けられています。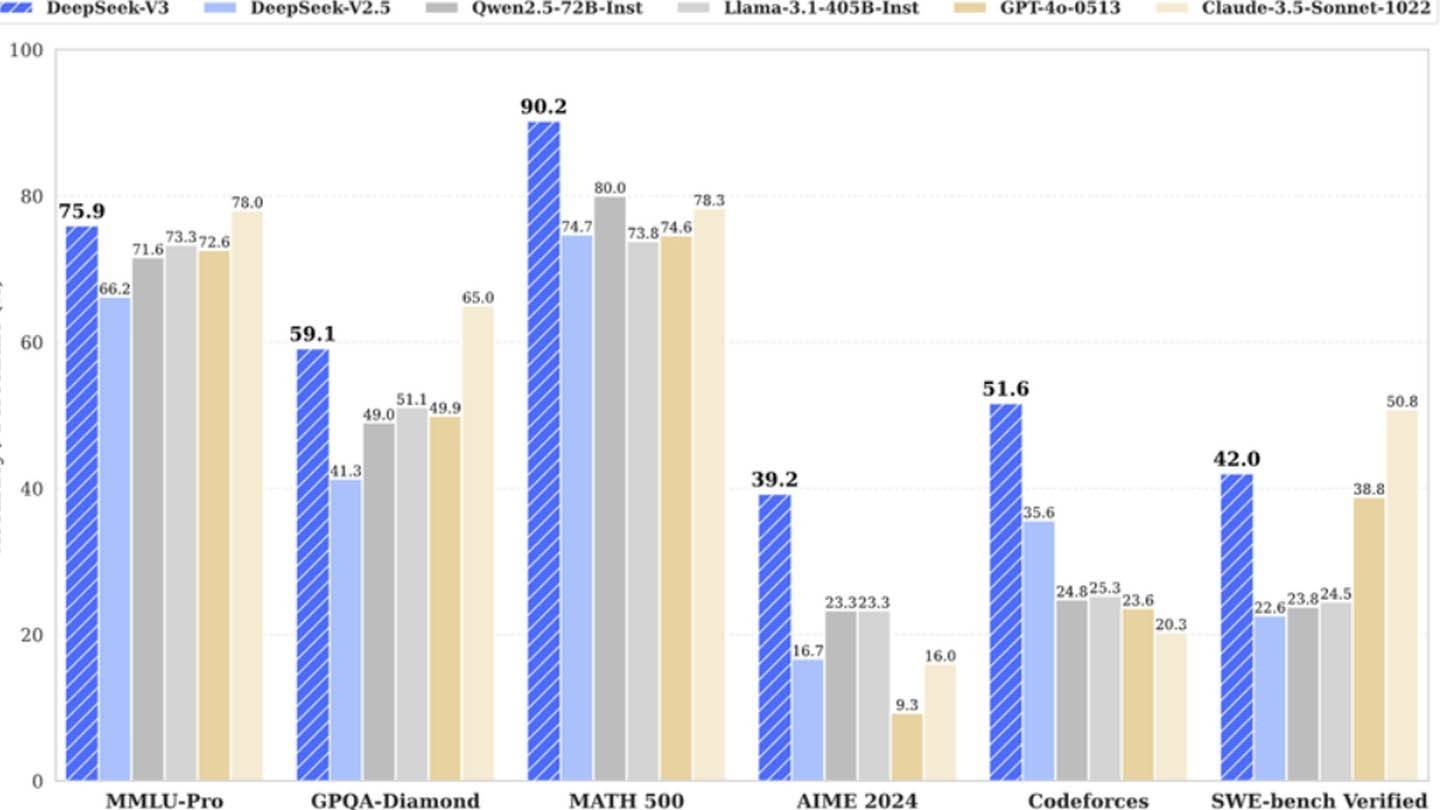 画像:endigame.com
画像:endigame.com
Deepseek V3の革新的なアーキテクチャは、その効率に貢献しています。 主要なテクノロジーには、同時単語予測のためのマルチトークン予測(MTP)、256
sを利用した専門家(MOE)の混合、および重要な文要素に重点を置くためのマルチヘッド潜在的注意(MLA)が含まれます。 画像:endigame.com
画像:endigame.com
ただし、綿密な見方では、実質的なインフラストラクチャへの投資が明らかになります。 Semianalysisは、Deepseekが約50,000のNvidia Hopper GPUを使用していることを明らかにしました。 これは、研究、洗練、データ処理、および全体的なインフラストラクチャを除く、トレーニング前のGPU使用のみを占める600万ドルのトレーニングコスト請求とは対照的です。
画像:endigame.com 
 Deepseekの「予算に優しい」主張は誤解を招く一方で、競合他社に対する費用対効果は依然として顕著です。 同社のR1モデルは、CHATGPT4の1億ドルと比較して、500万ドルのトレーニングの費用がかかりました。 Deepseekの例は、最初のコスト請求の誇張にもかかわらず、資金提供された機敏なAI企業が確立されたプレーヤーと効果的に競争する可能性を示しています。 現実は重要な投資、技術の進歩であり、熟練した労働力がその成功の鍵です。
Deepseekの「予算に優しい」主張は誤解を招く一方で、競合他社に対する費用対効果は依然として顕著です。 同社のR1モデルは、CHATGPT4の1億ドルと比較して、500万ドルのトレーニングの費用がかかりました。 Deepseekの例は、最初のコスト請求の誇張にもかかわらず、資金提供された機敏なAI企業が確立されたプレーヤーと効果的に競争する可能性を示しています。 現実は重要な投資、技術の進歩であり、熟練した労働力がその成功の鍵です。