โมเดล AI ราคาไม่แพงอย่างน่าประหลาดใจของ Deepseek ท้าทายยักษ์ใหญ่ในอุตสาหกรรม การเริ่มต้นของจีนอ้างว่าได้ฝึกฝน Deepseek V3 ที่ทรงพลังของมันสำหรับเพียง 6 ล้านเหรียญสหรัฐโดยใช้ GPU ในปี 2048 เพียงปี 2048 อย่างไรก็ตามค่าใช้จ่ายที่ดูเหมือนต่ำนี้เป็นการลงทุนที่ใหญ่กว่ามาก
 รูปภาพ: Ensigame.com
รูปภาพ: Ensigame.com
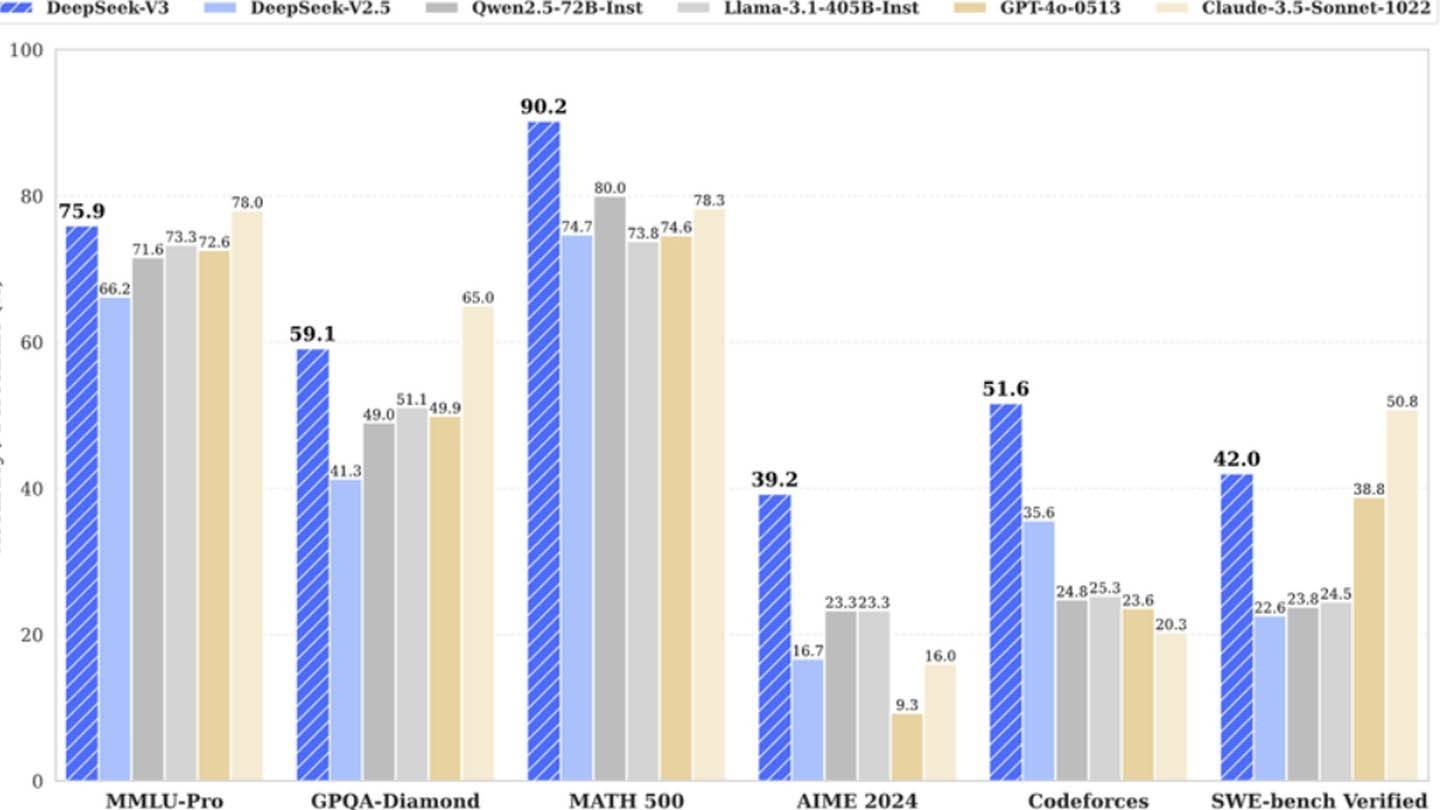
สถาปัตยกรรมที่เป็นนวัตกรรมของ Deepseek V3 มีส่วนช่วยในการมีประสิทธิภาพ เทคโนโลยีที่สำคัญ ได้แก่ การทำนายแบบมัลติเทน (MTP) สำหรับการทำนายคำพร้อมกันการผสมผสานของผู้เชี่ยวชาญ (MOE) โดยใช้ 256
s และความสนใจแฝงหลายหัว (MLA) เพื่อเพิ่มการมุ่งเน้นไปที่องค์ประกอบประโยคที่สำคัญ

อย่างไรก็ตามการมองอย่างใกล้ชิดเผยให้เห็นการลงทุนโครงสร้างพื้นฐานที่สำคัญ Semianalysis เปิดการใช้งานของ Deepseek ประมาณ 50,000 Nvidia Hopper GPUs รวมเป็นจำนวนเงินประมาณ 1.6 พันล้านเหรียญสหรัฐในค่าใช้จ่ายเซิร์ฟเวอร์และค่าใช้จ่ายในการดำเนินงาน 944 ล้านดอลลาร์ สิ่งนี้ตรงกันข้ามกับการเรียกร้องค่าใช้จ่ายในการฝึกอบรมเริ่มต้น $ 6 ล้านซึ่งมีเพียงบัญชีสำหรับการใช้งาน GPU ก่อนการฝึกอบรมไม่รวมการวิจัยการปรับแต่งการประมวลผลข้อมูลและโครงสร้างพื้นฐานโดยรวม

ความสำเร็จของ Deepseek เกิดจากโครงสร้างอิสระทำให้สามารถสร้างนวัตกรรมอย่างรวดเร็วและการจัดสรรทรัพยากรที่มีประสิทธิภาพ บริษัท ซึ่งเป็น บริษัท ในเครือของกองทุนป้องกันความเสี่ยงสูงเป็นเจ้าของศูนย์ข้อมูลซึ่งแตกต่างจากคู่แข่งที่พึ่งพาคลาวด์ นอกจากนี้เงินเดือนสูงยังดึงดูดความสามารถสูงสุดจากมหาวิทยาลัยจีน การลงทุนทั้งหมดของ Deepseek ในการพัฒนา AI เกิน $ 500 ล้าน

ในขณะที่การเรียกร้อง "ที่เป็นมิตรกับงบประมาณ" ของ Deepseek นั้นทำให้เข้าใจผิด แต่ความคุ้มค่าที่เกี่ยวข้องกับคู่แข่งยังคงโดดเด่น รุ่น R1 ของ บริษัท มีค่าใช้จ่าย 5 ล้านดอลลาร์ในการฝึกอบรมเมื่อเทียบกับ $ 100 ล้านของ CHATGPT4 ตัวอย่างของ Deepseek นำเสนอศักยภาพของ บริษัท AI ที่ได้รับการสนับสนุนและได้รับการสนับสนุนอย่างดีในการแข่งขันอย่างมีประสิทธิภาพกับผู้เล่นที่จัดตั้งขึ้นแม้จะมีการเรียกร้องค่าใช้จ่ายเริ่มต้น ความจริงคือการลงทุนที่สำคัญความก้าวหน้าทางเทคโนโลยีและพนักงานที่มีทักษะเป็นกุญแจสู่ความสำเร็จ Neural Network














