Deepseek yang mengejutkan model AI yang murah mencabar gergasi industri. Permulaan Cina mendakwa telah melatih Deepseek V3
yang kuat untuk hanya $ 6 juta, hanya menggunakan 2048 GPU, dengan ketara pemotongan pesaing. Walau bagaimanapun, kos yang rendah ini, memungkiri pelaburan yang lebih besar.
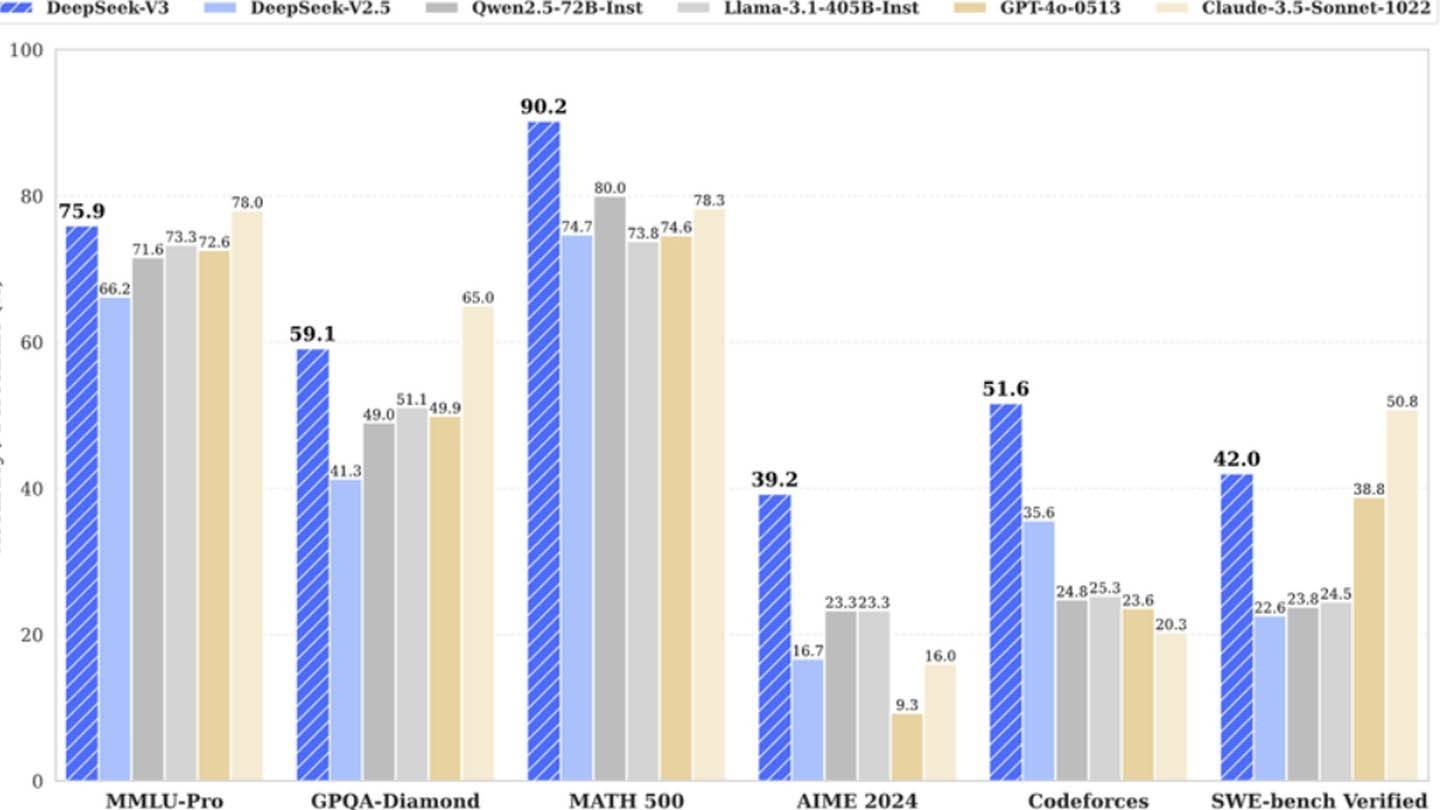
Senibina inovatif DeepSeek V3 menyumbang kepada kecekapannya. Teknologi utama termasuk ramalan multi-token (MTP) untuk ramalan perkataan serentak, campuran pakar (MOE) yang menggunakan 256
s, dan perhatian laten multi-kepala (MLA) untuk fokus yang dipertingkatkan pada unsur-unsur kalimat yang penting.

Walau bagaimanapun, penampilan yang lebih dekat mendedahkan pelaburan infrastruktur yang besar. Semianalysis mendedahkan penggunaan DeepSeek kira -kira 50,000 NVIDIA Hopper GPU, berjumlah sekitar $ 1.6 bilion dalam kos pelayan dan perbelanjaan operasi $ 944 juta. Ini berbeza dengan tuntutan kos latihan awal $ 6 juta, yang hanya menyumbang penggunaan GPU pra-latihan, tidak termasuk penyelidikan, penghalusan, pemprosesan data, dan infrastruktur keseluruhan.
 Imej: ensigame.com
Imej: ensigame.com
Kejayaan DeepSeek berpunca dari struktur bebasnya, yang membolehkan inovasi pesat dan peruntukan sumber yang cekap. Syarikat itu, anak syarikat dana lindung nilai yang tinggi, memiliki pusat datanya, tidak seperti pesaing awan. Selain itu, gaji yang tinggi menarik bakat teratas dari universiti -universiti Cina. Jumlah pelaburan DeepSeek dalam pembangunan AI melebihi $ 500 juta.
 Imej: ensigame.com
Imej: ensigame.com
Walaupun tuntutan "mesra bajet" Deepseek adalah mengelirukan, keberkesanan kosnya berbanding pesaing tetap ketara. Model R1 syarikat kos $ 5 juta untuk melatih, berbanding $ 100 juta ChatGPT4. Contoh DeepSeek mempamerkan potensi syarikat AI yang dibiayai dengan baik untuk bersaing dengan pemain yang ditubuhkan, walaupun keterlaluan tuntutan kos awalnya. Kenyataannya adalah pelaburan yang signifikan, kemajuan teknologi, dan tenaga kerja mahir adalah kunci kejayaannya.














