Ang nakakagulat na murang mga hamon sa modelo ng AI Model ay mga higante sa industriya. Sinasabi ng Startup ng Tsino na sinanay ang malakas na Deepseek V3
para sa isang $ 6 milyon lamang, na gumagamit lamang ng 2048 GPU, na makabuluhang sumailalim sa mga kakumpitensya. Ang tila mababang gastos na ito, gayunpaman, ay nagtatakip ng isang mas malaking pamumuhunan.
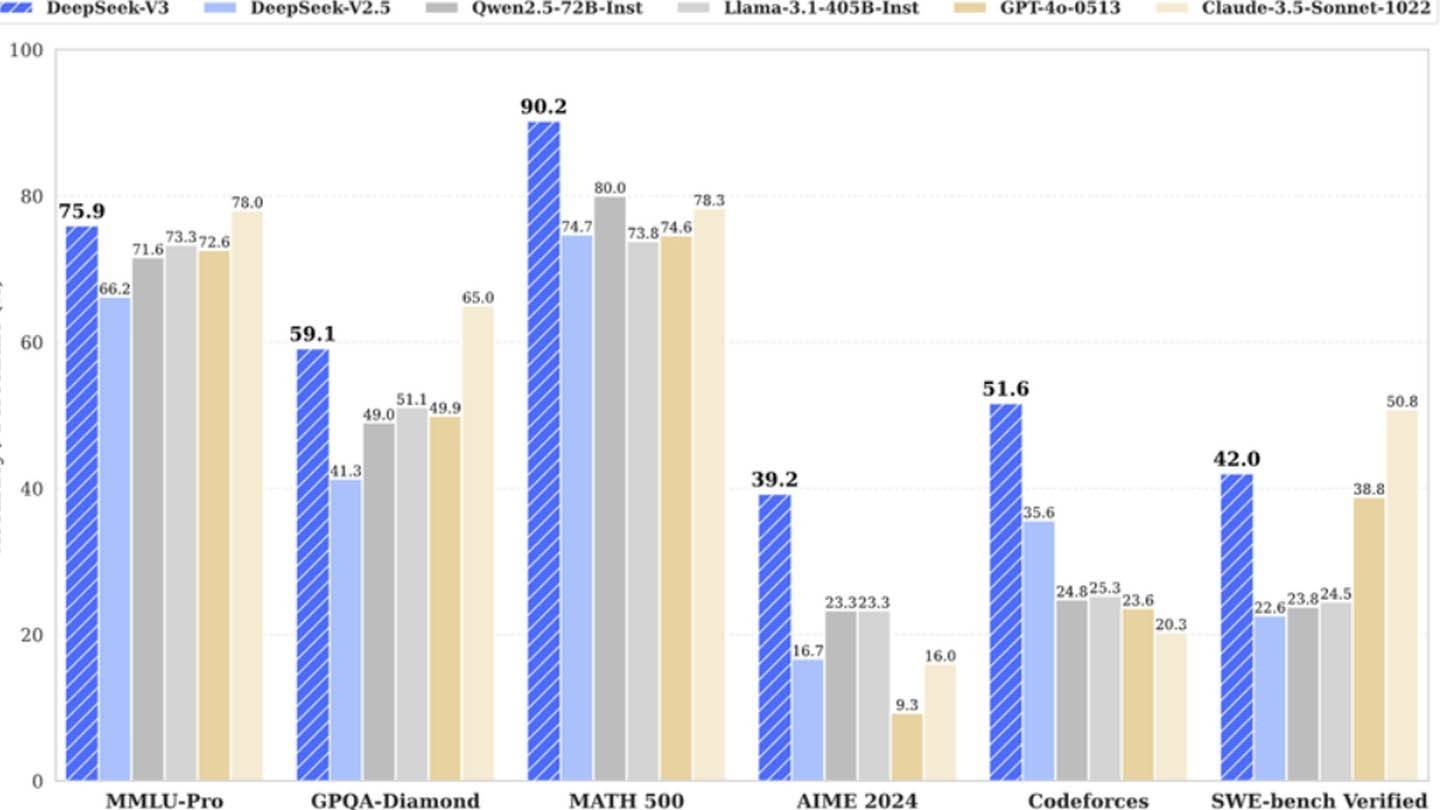
Ang makabagong arkitektura ng Deepseek V3 ay nag -aambag sa kahusayan nito. Ang mga pangunahing teknolohiya ay may kasamang multi-token prediction (MTP) para sa sabay-sabay na hula ng salita, pinaghalong mga eksperto (MOE) na gumagamit ng 256
s, at multi-head latent attention (MLA) para sa pinahusay na pokus sa mga mahahalagang elemento ng pangungusap.

Gayunpaman, ang isang mas malapit na hitsura ay nagpapakita ng isang malaking pamumuhunan sa imprastraktura. Ang Semianalysis ay walang takip na paggamit ng Deepseek na humigit -kumulang na 50,000 NVIDIA HOPPER GPU, na umaabot sa $ 1.6 bilyon sa mga gastos sa server at $ 944 milyon sa mga gastos sa pagpapatakbo. Ito ay kaibahan nang matindi sa paunang $ 6 milyong pag-angkin ng gastos sa pagsasanay, na ang mga account lamang para sa paggamit ng pre-training GPU, hindi kasama ang pananaliksik, pagpipino, pagproseso ng data, at pangkalahatang imprastraktura.
 Imahe: ensigame.com
Imahe: ensigame.com
Imahe: ensigame.com 














