DeepSeek's surprisingly inexpensive AI model challenges industry giants. The Chinese startup claims to have trained its powerful DeepSeek V3 neural network for a mere $6 million, utilizing only 2048 GPUs, significantly undercutting competitors. This seemingly low cost, however, belies a much larger investment.
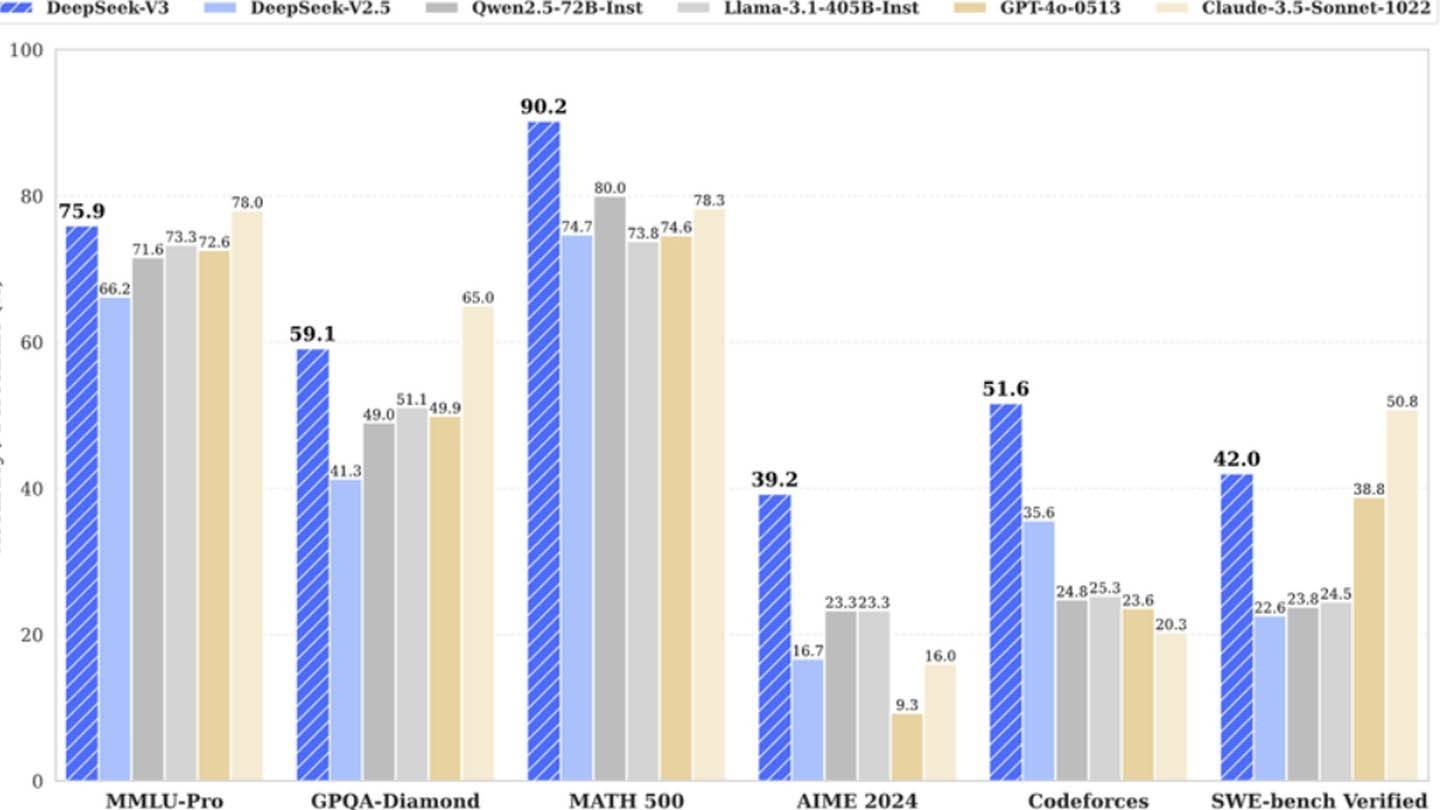 Image: ensigame.com
Image: ensigame.com
DeepSeek V3's innovative architecture contributes to its efficiency. Key technologies include Multi-token Prediction (MTP) for simultaneous word prediction, Mixture of Experts (MoE) utilizing 256 neural networks, and Multi-head Latent Attention (MLA) for enhanced focus on crucial sentence elements.
 Image: ensigame.com
Image: ensigame.com
However, a closer look reveals a substantial infrastructure investment. SemiAnalysis uncovered DeepSeek's use of approximately 50,000 Nvidia Hopper GPUs, totaling around $1.6 billion in server costs and $944 million in operational expenses. This contrasts sharply with the initial $6 million training cost claim, which only accounts for pre-training GPU usage, excluding research, refinement, data processing, and overall infrastructure.
 Image: ensigame.com
Image: ensigame.com
DeepSeek's success stems from its independent structure, allowing for rapid innovation and efficient resource allocation. The company, a subsidiary of High-Flyer hedge fund, owns its data centers, unlike cloud-reliant competitors. Furthermore, its high salaries attract top talent from Chinese universities. DeepSeek’s total investment in AI development exceeds $500 million.
 Image: ensigame.com
Image: ensigame.com
While DeepSeek's "budget-friendly" claim is misleading, its cost-effectiveness relative to competitors remains notable. The company's R1 model cost $5 million to train, compared to ChatGPT4's $100 million. DeepSeek's example showcases the potential of a well-funded, agile AI company to compete effectively with established players, despite the exaggeration of its initial cost claims. The reality is a significant investment, technological advancements, and a skilled workforce are key to its success.














